- This topic has 9 replies, 5 voices, and was last updated 6 years ago by
 Bill Finzer.
Bill Finzer.
-
AuthorPosts
-
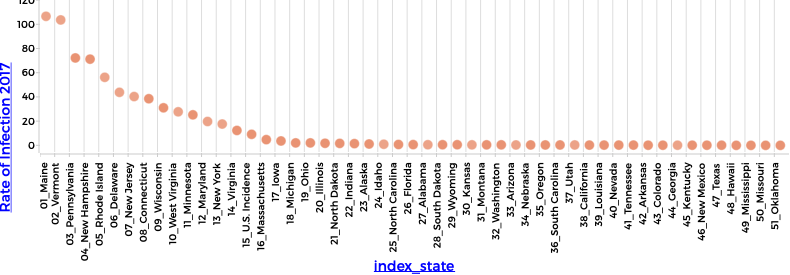
I have a data set with the states of the US in one column and a number (e.g. incidence of Lyme disease) in the second. I would like to make a graph that has state on the X-axis and incidence on the Y-axis but I would like the states to be plotted in order of increasing values of incidence. So, I sorted the table by the numerical variable, then plotted state on the X-axis and incidence on the Y-axis — but the states still came out in alphabetical order. Is there a way around this? It does seem like something people would want to do with a categorical and a numerical variable.
Link to dataset: http://bit.ly/lyme17
January 6, 2019 at 6:13 pm #801Bill FinzerKeymasterHi Andee,
So you didn’t want to drag the states to the desired order?
I was stuck for quite a while and almost gave up the search for an automated solution. But, as you can see in the screen captures, I was able to create a new attribute whose alphabetic order is in order of decreasing incidence.
So that gives you a “workaround” but it’s hardly a generally useful solution.
One wrinkle is that most of the time a given category (State in this case) has more than one value. So you would have to plot something like a mean to have single-values to order by. Then you could have a command somewhere in the graph interface to Order by Value.
But do we want to add something to the interface to automate a task seldom encountered and that can be done manually?
Bill
Attachments:
January 6, 2019 at 6:58 pm #804No, I didn’t want to drag 50 states into the right order, especially when some of the values are relatively close and I couldn’t see them well. (Or maybe you weren’t seriously asking that?)
I actually disagree that most of the time there would be multiple values for a single category – maybe that’s the case in the data you’ve been working with, but it’s not the case in most of the data I’ve been working with. Consider, for example, any data set that has one row/case per person – and several numbers associated with each person (height, weight, shoe size, etc.) and I’d like to see the distribution of heights as a case value plot, ordered, in the way they would be if people were standing in a line.
Perhaps the whole realm of case-value plots is not one that CODAP wants to support – but I would argue, at least for the age group I’m working with, they are a very useful representational form for students to work with, certainly before they learn to write formulas. (I’m not quite sure how the formula works, by the way – can you explain? But it’s certainly not an entry-level formula..)
January 7, 2019 at 3:24 pm #805 Dan DamelinKeymaster
Dan DamelinKeymasterOne possibility would be to add some options to the menu that pops up when you click an axis title. If the axis is categorical we could provide a “Sort…” submenu and give options like [alphabetically (ascending), alphabetically (descending), by value (ascending), by value (descending)]. I think it needs some design thinking, but may be possible.
January 7, 2019 at 4:39 pm #806I’m still a little confused about why this DOESN”T work…If I sort the TABLE, then the rows are in a different order – why don’t they end up on the graph that way?
January 8, 2019 at 12:04 am #807Bill FinzerKeymasterRegarding the connection between case order in the table and order of categories: We regard these two things as conceptually distinct. Suppose, for example that you have census records of people, each with a marital status. We don’t say that the order of the records should determine the order in which ‘married,’ ‘divorced,’ ‘never married,’ etc should appear on a categorical axis. The default order is alphabetical, and the user can change that order manually.
But perhaps this brings up a research question: How do learners regard categorical values, and how do they come to understand the different ways they can be used in data visualization and analysis?
January 8, 2019 at 12:27 am #808Bill FinzerKeymasterHi Andee,
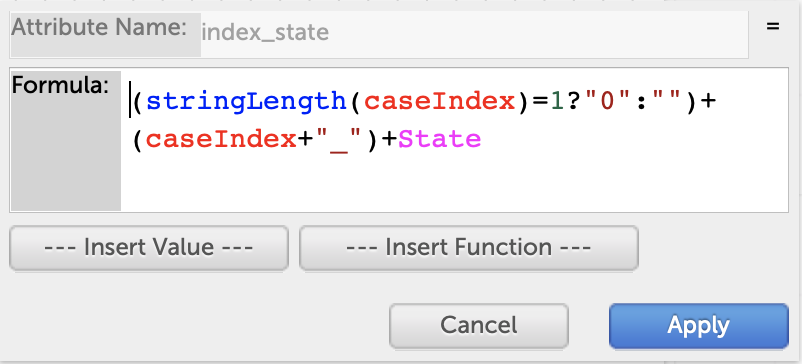
Regarding the formula workaround, I just thought of a simplification:
(caseIndex+10)+”_”+State
The goal is that the computed value sort alphabetically to the same order as the states appear in the table.
caseIndex is the row number in the table. By adding 10, we avoid the complication that alphameric sorting places “10_” before “2_”. So once the states are sorted in decreasing order of Lyme disease incidence, the values computed by the formula will also sort in that order and that will be the default order in which they appear on a categorical axis.
Confusing? You bet! 🙂
January 24, 2019 at 12:39 am #813 Tim EricksonParticipant
Tim EricksonParticipantAnother take on this: Andee’s situation is one in which the State’s name or abbreviation is _unique_ in the data set. If we knew an attribute was not only categorical but also unique, we could conceivably do what Andee found natural: sort the table any way you want, and then plot the cases.
I bet it would not be too hard (ha ha ha) to determine automatically if an attribute had this “unique” property.
This may be part of the broader issue of “roles of attributes” where another one we have discussed is “time-like,” so that some time-series things might happen naturally in visualizations if it were on an axis.
January 29, 2020 at 6:41 pm #1285Michelle Wilkerson
ParticipantHi CODAP friends,
I see I’m reopening a year-old topic, but we just had a similar experience yesterday. One student wanted to “sort the x axis by the y axis” – something like a Pareto histogram, where (in this case, many) categorical variables on the x-axis are organized so that the quantitative variable on the y-axis descends from left to right. It wasn’t obvious to me how they could do this easily, other than manually dragging the categorical variables around.
I just wanted to add another data point to this being a feature that could be useful. We also tried the table sorting method described above (another student sitting next to this one proposed it). The student was working with CODAP for the first time when they suggested wanting to make this particular move, and I was a bit hesitant to pull up the attribute formula interface and clunk my way through it, but I will show that to the student next time I see them.
January 29, 2020 at 9:56 pm #1287Bill FinzerKeymasterHi Michelle,
Thanks for adding “another data point.” You’ve shifted its priority.
Bill
-
AuthorPosts
- You must be logged in to reply to this topic.